Learning associations across modalities is critical for robust multimodal reasoning, especially when a modality may be missing during inference. In this paper, we study this problem in the context of audio-conditioned visual synthesis – a task that is important, for example, in occlusion reasoning. Specifically, our goal is to generate future video frames and their motion dynamics conditioned on audio and a few past frames.
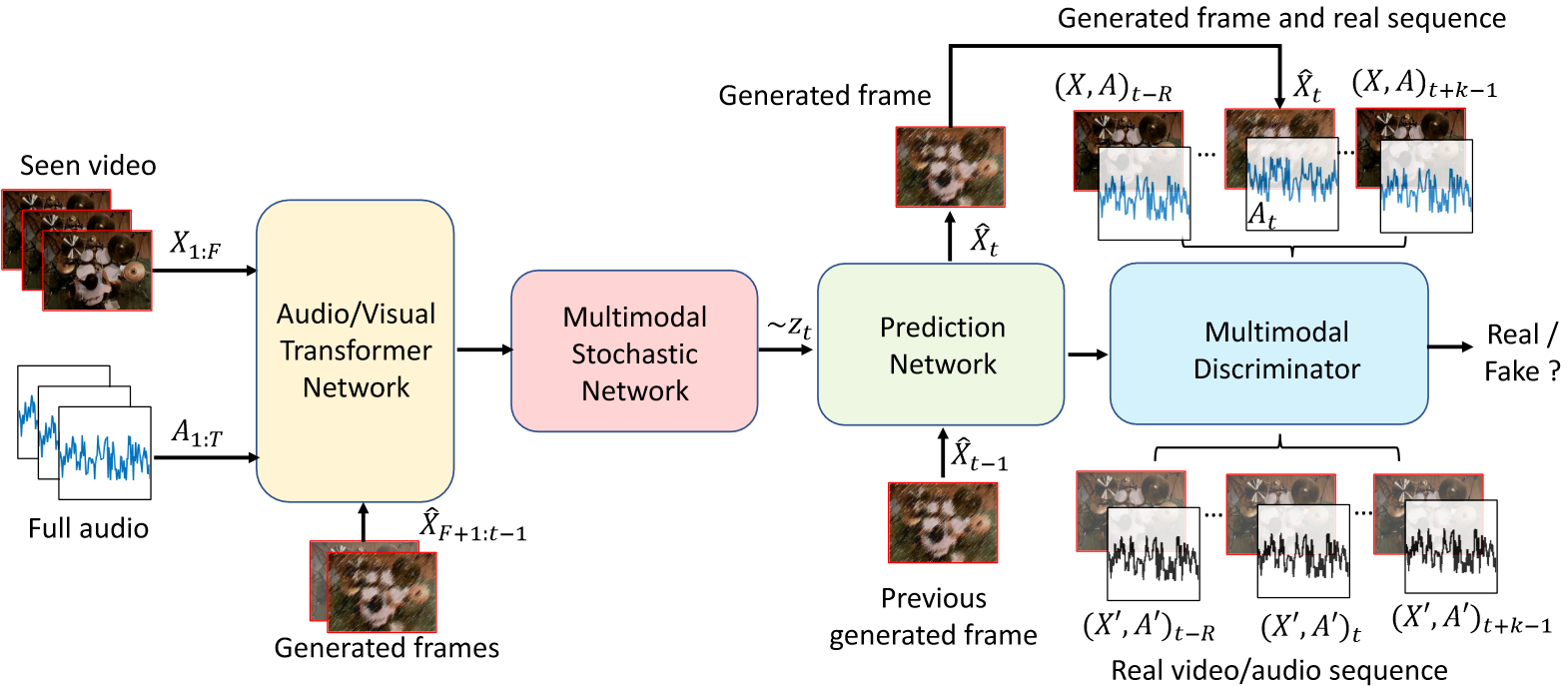
Sound2Sight: Generating Visual Dynamics from Sound and Context
Read More “Sound2Sight: Generating Visual Dynamics from Sound and Context”