We present a segmentation algorithm to detect low-level structure present in images. The algorithm is designed to partition a given image into regions, corresponding to image structures, regardless of their shapes, sizes, and levels of interior homogeneity. We model a region as a connected set of pixels that is surrounded by ramp edge discontinuities where the magnitude of these discontinuities is large compared to the variation inside the region.
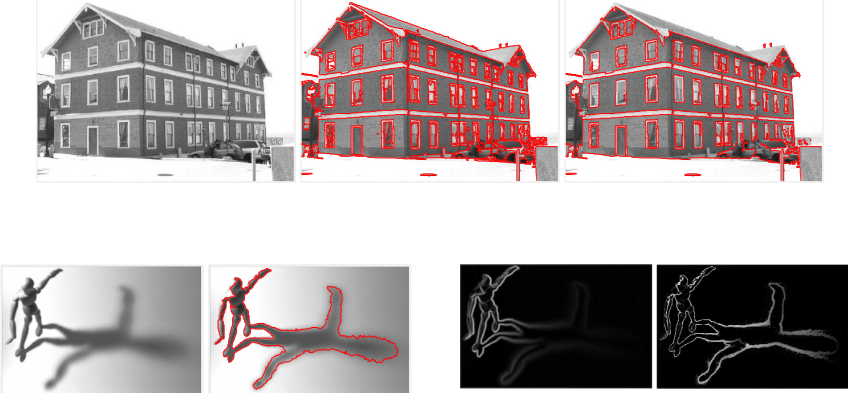
Low-Level Multiscale Image Segmentation and a Benchmark for its Evaluation
Read More “Low-Level Multiscale Image Segmentation and a Benchmark for its Evaluation”